什么是一致性 Hash 算法?
"一致性 Hash" 似乎是一个具有迷惑性的名字,因为 Hash 函数的结果不管在哪里计算都应该是一样的,为什么会存在一致性的问题? 其实我们提出一致性 Hash 这个概念是为了解决分布式存储中的问题。在分布式存储中不同的机器会存储不同的对象的数据,我们使用 Hash 函数来建立数据到服务器之间的映射关系。那么为什么会存在 "不一致" 呢?
Hash 的不一致是指什么?
我们考虑这样一个分布式存储的场景:
现在需要将 10 个数据 存放到 3 个机器节点 ( ) 上。我们当然可以使用一个映射表来维护数据和机器之间的映射关系,但是那样意味着我们需要额外存储一个表,而且必须不断维护它。甚至这个表可能会随着数据的增加会存储不下。那么我们自然会想到使用一个 Hash 函数来计算数据和机器节点之间的映射,于是我们有了以下这个公式:
其中 为数据对象的名称, 为机器的数量, 为计算出存储对象的机器节点编号。
根据这个公式我们很容易得到以下映射:
| 机器编号 | 数据 |
|---|---|
| 0 | |
| 1 | |
| 2 |
表 1
如果我们此时增加一个机器, 后,可以重新计算得出映射:
| 机器编号 | 数据 |
|---|---|
| 0 | |
| 1 | |
| 2 | |
| 3 |
表 2
很显然,除了 没有改变机器节点以外,其他所有的数据都变更了存储机器。这意味着当存储集群中增加一个机器节点时会造成大量的数据迁移,这无疑给网络和磁盘增加了许多压力,严重情况下也可能导致数据库的宕机。
所以 Hash 的一致性并不是指 Hash 函数重复计算之后结果不一致,而是这种计算导致了数据的迁移。那么我们有没有可能减少这种数据的迁移呢? 可以的,一致性 Hash 算法可以保证当机器节点增加或者减少时,节点之间的数据迁移只限于两个节点之间,而不会造成全局的网络问题。
一致性 Hash 的使用场景
一致性 Hash 算法是分布式系统中非常重要的算法,主要运用在:
- 负载均衡。
- 缓存数据分区。
- 分布式关系型数据库节点映射。
- RPC 框架 Duddo 用来选择服务提供者。
算法实现
整个算法主要是将 Hash 值空间转移到一个环状的虚拟空间上,然后再对机器节点和数据进行映射。我们就根据前文提到的数据与机器节点映射的例子具体来看一下实现的过程:
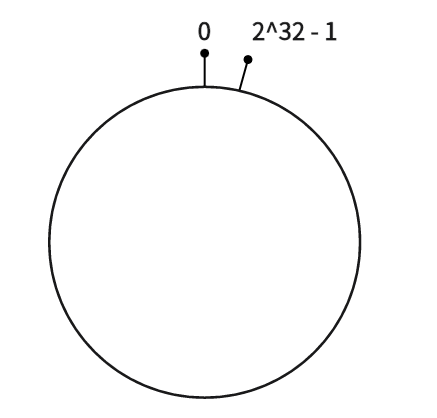
创建 Hash 环。 不同于一般 Hash 函数将数据映射到一个线性的空间,我们考虑将 Hash 值空间映射成一个虚拟的环状空间。如果整个 Hash 空间的取值为:,那么我们按照顺时针排列,让最后一个节点 在开始位置 0 重合。
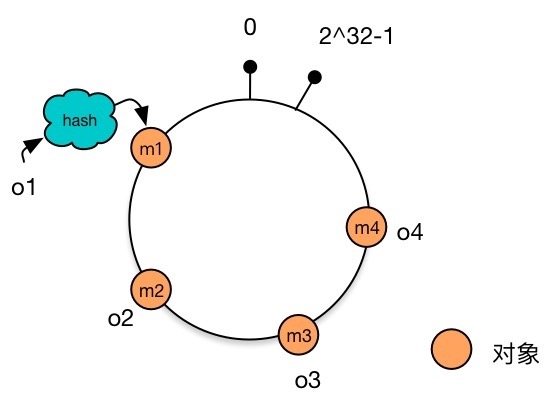
环状 Hash 空间 将数据映射到 Hash 环上。 假设现在有 4 个数据对象 ,分别对其计算 Hash 值,得到结果 。将这四个结果放置到 Hash 环上。
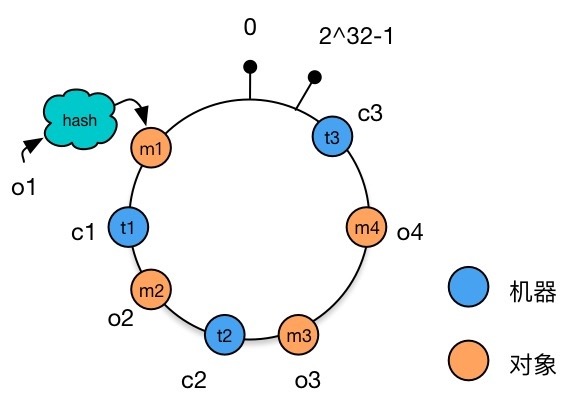
数据对象映射到 Hash 环上 将服务器映射到 Hash 环上。 对 3 台服务器 的 IP 地址进行 Hash 计算,对 Hash 值进行 取模,得到一个取值在 的整数 。将取模后的整数映射在 Hash 环上。
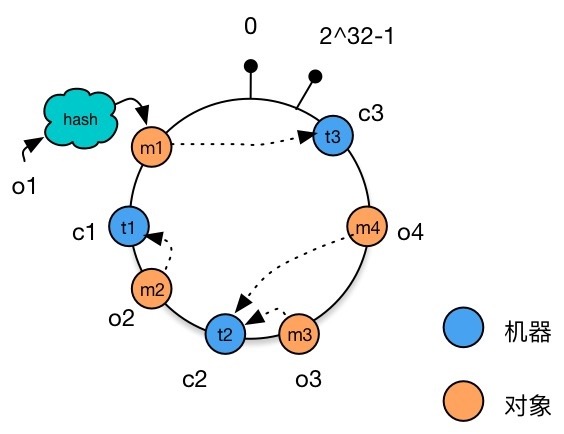
机器节点映射到 Hash 环上 为数据选择存储的机器节点。 每个数据对象都按照顺时针方向选择离自己最近的机器进行存储。
数据对象选取机器节点
以上我们就完成了整个一致性 Hash 算法的计算过程。接下来我们分别看一下对于文章开始提到的两个场景:增加机器节点和删减机器节点时数据和机器之间的映射会发生哪些改变。
增加机器节点
现在增加一台机器 ,Hash 值取模后得到整数 ,将其加入 Hash 环。
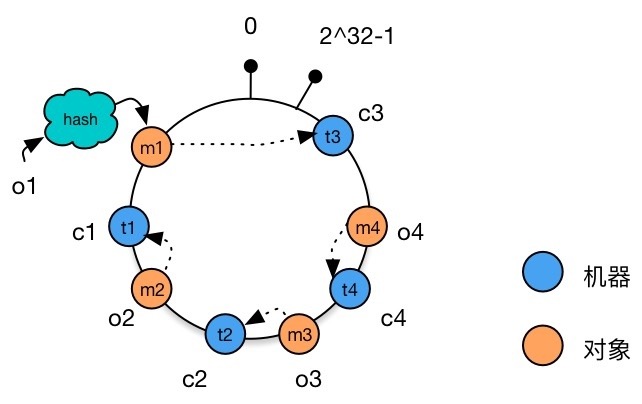
可以看到不同于表 1 和表 2 中大量数据需要变更机器节点的情况,现在我们只需要变更一个数据对象 ,将其从 重新分配至 。
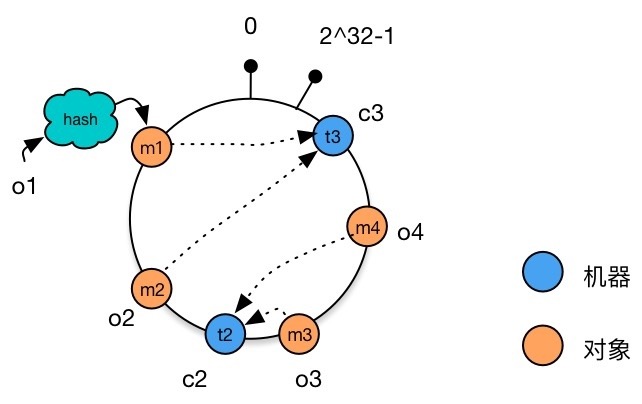
减少机器节点
同样,如果我们减少一台机器 ,重新分配机器后发现,只有对象 被重新分配到了 ,而其他的数据无需变动。
可能遇到的问题
负载不均衡。
这是一致性 Hash 很容易遇到的一个问题。通常来说我们希望数据均匀地分布在所有机器上,包括增加或删除机器之后。但是观察之前提到的 增加节点 的例子,增加机器 之后,仅仅分担了 的压力。我们可以想象,如果再一次增加节点 ,不幸新的节点的 Hash 值又一次地落在了 和 之间,那么新增的节点分配不到任何数据。可见新增机器节点未必一定能减轻数据负载的压力。
那么该如何解决呢?我们可以使用 虚拟节点。
还是沿用上述的例子:对于机器 来说,除了直接映射到 Hash 环上形成三个节点外,每个节点还额外拥有两个虚拟节点。当虚拟节点越多,也就意味着数据在机器上分布得越均匀。
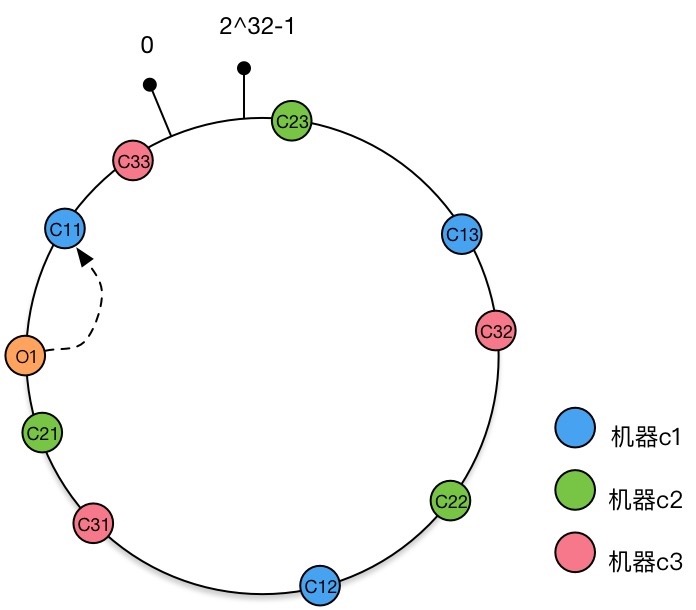
你可以理解为我们又增加了一层虚拟机器节点到实际机器节点的映射。
总结
一致性 Hash 算法解决了分布式环境下机器增加或者减少时,简单的取模运算无法获取较高命中率的问题。
通过虚拟节点的使用,一致性 Hash 算法可以均匀分担机器的负载,使得这一算法更具现实的意义。
