- 原子性 ( Atomicity ) 。 指一个事务其中的操作要么都做,要么都不做。
- 一致性 ( Consistency ) 。 指事务执行完成时,必须使所有的数据都保持一致状态。
- 隔离性 ( Isolation ) 。 指事务内部的操作与其他事务时隔离的,并发执行的各个事务之间不产生干扰。
- 持久性 ( Durability ) 。 指事务一旦提交,对数据库的改变是永久性的,接下来的故障不应该对其有任何影响。
NoSQL 数据库是什么?
简介
NoSQL 是对非关系型数据库的统称。它所采用的数据库模型并非传统关系数据库的关系模型,而是类似键值对、族列、文档等非关系模型。NoSQL 数据库没有固定的表结构,通常也不存在连接操作,也没有严格遵守 ACID 约束。
通常 NoSQL 数据库拥有以下 3 个特点:
灵活的可扩展性。
传统的关系型数据库由于自身设计机理的原因,通常很难实现「横向扩展」,在面对负载大规模增加的情况往往需要通过升级硬件来「纵向扩展」。但是目前的计算机硬件制造已经很难赶上数据增加的速度。相反,「横向扩展」仅仅需要非常廉价的标准化刀片服务器。
灵活的数据模型。
关系模型是关系数据库的基石,它以完备的关系代数理论为基础,具有规范的定义,遵守各种严格的约束。相反,NoSQL 数据库摒弃了束缚,采用非关系模型,允许在一个数据元素中存储不同类型的数据。
与云计算紧密融合。
云计算具有很好的水平扩展能力,可以根据资源使用情况进行自由伸缩,各种资源可以动态加入和退出,与 NoSQL 的横向扩展很好地融合。
NoSQL 兴起的原因
关系数据库无法满足 Web 2.0 的需求
- 无法满足海量数据的管理需求。
- 无法满足数据高并发的需求。
- 无法满足高可扩展性和高可用性的需求。
关系数据库的关键特性在 Web 2.0 时代成为「鸡肋」
- Web 2.0 网站通常不要求严格的数据库事务。
- Web 2.0 并不要求严格的读写实时性。
- Web 2.0 通常不包含大量复杂的 SQL 查询。
NoSQL 与关系数据库的比较
| 标准 | 关系数据库 | NoSQL | 备注 |
|---|---|---|---|
| 数据库原理 | 完全支持 | 部分支持 | 关系数据库有关系代数理论作为基础。NoSQL 没有统一的理论基础。 |
| 数据规模 | 大 | 超大 | 关系数据库很难实现横向扩展,纵向扩展的空间也有限。NoSQL 可以很容易通过添加更多设备来支持更大规模的数据。 |
| 数据库模式 | 固定 | 灵活 | 关系数据库需要定义数据库模式,严格遵守数据定义和相关约束。NoSQL 不存在数据库模型,可以自由定义并存储各种不同类型的数据。 |
| 查询效率 | 快 | 可以实现高效的简单查询,但是不具备高度结构化查询的特性。 | 很多 NoSQL 数据库没有面向复杂查询的索引,虽然可以使用 MapReduce 来加速查询,但是复杂查询方面的性能仍然不如关系数据库。 |
| 一致性 | 强 | 弱 | 很多 NoSQL 数据库只遵循 BASE 模型,只能保证最终一致性。 |
| 数据完整性 | 容易实现 | 很难实现 | 关系数据库可以通过主键、非空约束来实现实体完整性,通过主键、外键来实现参照完整性。但是 NoSQL 数据库无法实现。 |
| 扩展性 | 一般 | 好 | |
| 可用性 | 好 | 很好 | 关系型数据库库任何时候都以保证数据一致性为优先目标,随着数据规模增大,只能提供相对较弱的可用性。 |
| 标准化 | 是 | 否 | 不同的 NoSQL 数据库有不同的查询语句。 |
| 技术支持 | 高 | 低 | |
| 可维护性 | 复杂 | 复杂 |
指数据库中数据的正确性、相容性。
- 正确性:保证进入数据库的数据是符合语义约束的合法数据。
- 相容性:同一个事实的两个数据应当是一致的。
NoSQL 的四大类型
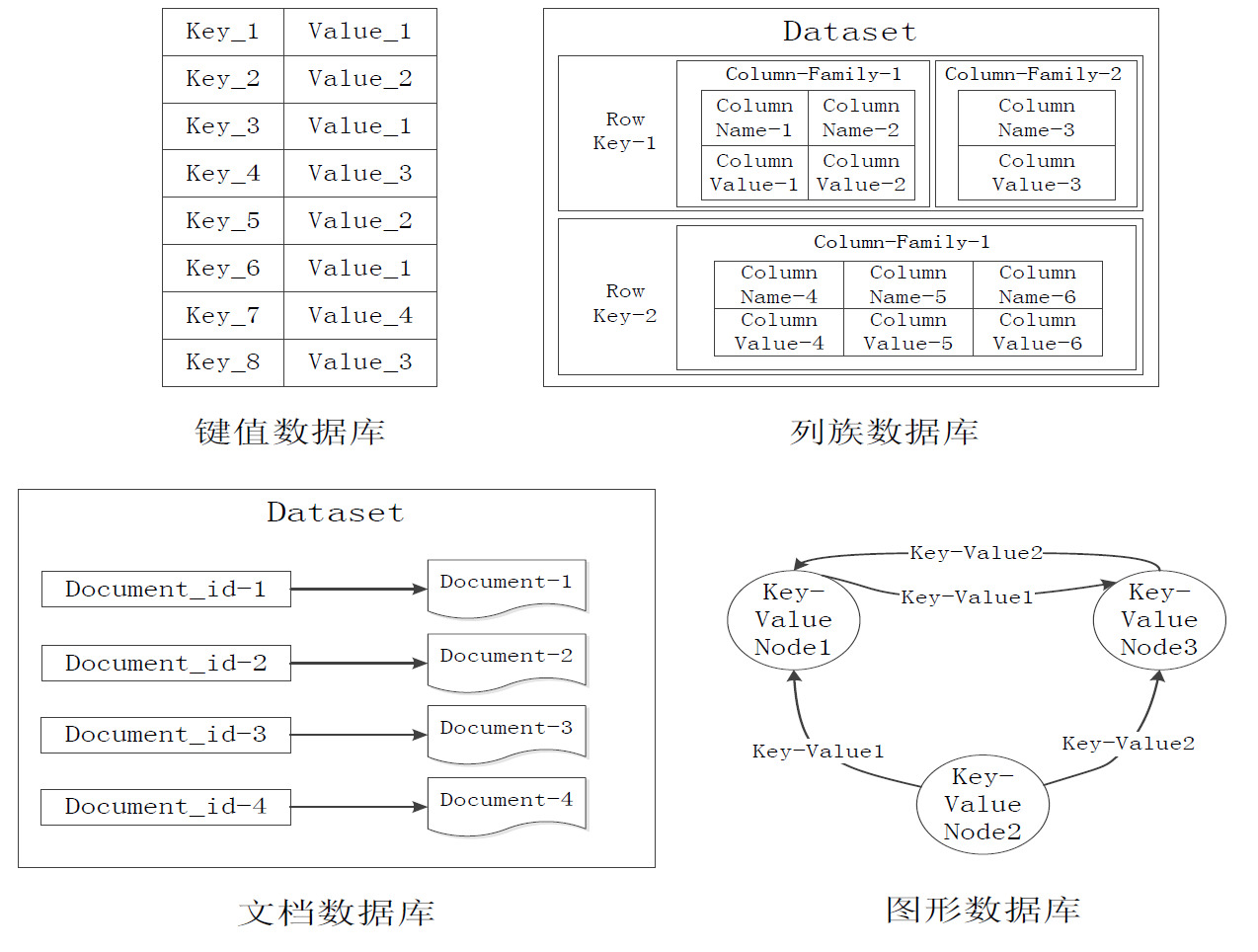
键值数据库 ( Key-Value Database )
键值数据库会使用搞一个哈希表,这个表中有一个特定的 Key 和一个指针指向特定的 Value. Value 对于数据库是透明不可见的,只能通过 Key 进行查询,不能反查。
在大量读写情况下,键值数据库可以比关系数据库取得更好的性能。因为,关系数据库需要建立索引来加速查询,大存在大量写操作时索引会频繁更新。
键值数据库可进一步分为:内存键值数据库和持久化键值数据库。内存键值包括:Redis, Memcache。持久化包括:BerkeleyDB, Voldmort 和 Riak。
键值数据库的缺点
条件查询。因此如果仅仅对部分值进行查询或更新,效率比较低下。多表关联查询需要尽力避免,或者采用双向荣誉存储关系来代替表关联。
列族数据库
数据库由多个行构成,每行数据包含多个列族,不同的行可以拥有不同数量的列族,属于统一列族的数据会被存放在一起。可以通过行键访问对应的列族。某种程度上可以看作一个键值数据库。
优点
: 查询快,可扩展性强,容易进行分布式,复杂度低。
缺点
功能少,不支持一致性。
文档数据库
文档数据库通过一个键来定位一个文档,可以看作时简直数据库的一个衍生品,但是具有更高的查询效率。
文档数据库既可以根据 Key 来构建索引,也可以基于文档内容。尤其是基于文档内容的索引和查询这种能力是文档数据库不同于键值数据库的地方。
优点
- 性能好。
- 灵活度高。
缺点
- 缺乏统一的查询语法。
图数据库
图数据库专门用来处理具有高度相互关联的数据,可以高效地处理实体之间的关系。Neo4J 可完全兼容 ACID。
优点
- 灵活度高。
- 支持复杂的图计算。
缺点
- 复杂性高。
- 只能支持一定的数据规模。
NoSQL 的三大基石
NoSQL 的三大基石包括 CAP,BASE 和 最终一致性。
CAP
- C:一致性。指任何一个读操作总是能够读到之前完成的写操作的结果。也就是分布式环境中,多点的数据是一致的。
- A:可用性。指快速获取数据,可以在确定的时间内返回操作结。
- P:分区容忍性。指当出现网络分区的情况 ( 一部分节点无法与其他节点通信 ) ,分离的系统也可以运行。
处理 CAP 问题的时候通常有以下几个选择:
- CA。强调一致性和可用性。最简单的做法是将所有与事务相关的内容都放到一个机器上。例如 MySQL, PostgreSQL 都采用该设计。
- CP。强调一致性和分区容忍性。当出现网络分区情况时,受影响的服务需要等待数据一致,等待期间无法对外提供服务。
- AP。强调可用性和分区容忍性。允许系统返回不一致的数据。对于 Web 2.0 的网站而言是可行的。例如发微博,如果不能立刻发布用户就会放弃使用。但是这个微博什么时候能够被其他用户读取到则不是非常重要的问题。当然采用 AP 的同时可以使用最终一致性。
BASE
BASE 的基本含义是:基本可用 ( Basically Availble ) ,软状态 ( Soft State ) ,最终一致性 ( Eventual Consistency ) 。
基本可用。
指分布式系统一部分不可用时,其他部分仍然可用正常使用,即允许分区失败情况。
软状态。
指状态可用有一段时间不同步,具有滞后性。例如转账的时候 A 的钱已经少了,但是 B 的钱还未增加。
最终一致性。
只需要最终数据是一致的就可以,无需实时保持一致。
最终一致性
从服务端的角度:一致性是指更新如何复制分布到整个系统,以保证数据最终一致。
从客户端的角度:一致性主要指的是高并发的数据访问操作下,后续操作是否能够获得最新数据。
最终一致性根据更新后各进程访问到数据的时间和方式不同可分为:
- 因果一致性。
- 「读自己写的」一致性。
- 会话一致性。
- 单调读一致性。
- 单调写一致性。
本文参考资料
贡献者

更新日志
2025/10/11 02:26
查看所有更新日志