布隆过滤器 ( Bloom Filter ) 的原理及应用
布隆过滤器是一种概率数据结构,用于检查集合中是否存在项目,在 LSM Tree 以及其他的大数据场景中有广泛的应用。
使用场景
布隆过滤器主要的使用场景是用于 快速判断一个元素是否在一个集合之中。通常用于过滤海量的数据请求以及提高对于数据的查找效率。例如刷抖音的时候,想要判断该视频是否已经被当前用户所收藏就是一个判断某元素是否在一个集合的问题,我们可以使用布隆过滤器来提高查询的效率。
基本原理
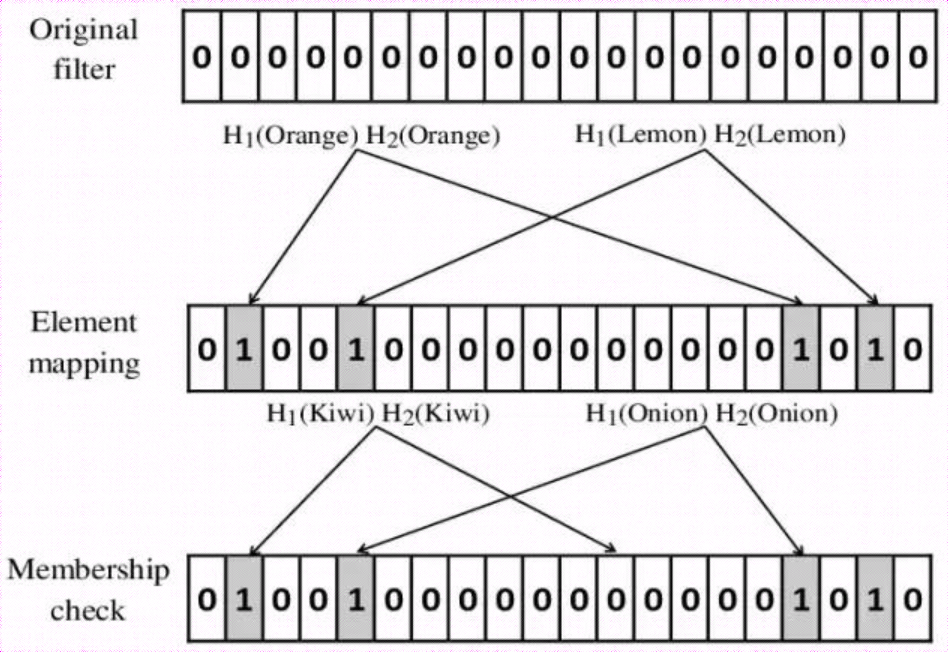
布隆过滤器是一种具有空间优势的概率数据结构,核心就是一个超大的位数组和哈希函数,用于回答一个元素是否存在于一个集合中这样的问题,但是可能会出现误判——即一个元素不在集合但被认为在集合中。
- 给定长度为 N 个 bits 的哈希空间。
- 选取 d 个哈希函数,每个哈希函数将给定的元素映射到 [0, N-1] 的一个位置上,并将该位置为 1。
- 将需要被判断的元素也用 2 中的 d 个哈希函数算出 d 个位置 。
- 如果 对应的位有一个不为 1,则该元素一定不在集合中。
- 如果 对应的位全为 1,则该元素可能存在于集合中。
参数
从上面可以看出,一个布隆过滤器应该起码有以下参数:
- 哈希空间大小,记为 。以上示例中 = 20 bits。
- 元素集合大小,记为 。以上示例中 = 2。
- 哈希函数个数,记为 。以上示例中 = 2。
- 因为 BF 是 Allowable Errors 的,可能会出现一个元素原本不在集合中,但是被错判为存在于集合中,这个错判的概率叫 false postive,记为 。
当错误率最小的时候,各个参数之间会有如下关系:
如何选择哈希函数?
从概率计算和速度角度,哈希函数需满足:
- 独立且均匀分布。
- 计算速度快。
这里推荐了解 murmur 算法。
优缺点
优点
- 内存效率高。
- 查询速度快。
- 可并行处理。
缺点
- 存在误判率。主要取决于哈希函数的数量和位数组的大小,较大的位数组可以降低误判率,但会增加内存消耗,因此需要权衡。
- 存在哈希冲突。
- 不支持删除。
- 不能获取原始数据。
应用
- 数据库防止穿库。使用 BloomFilter 来减少不存在的行或列的磁盘查找。避免代价高昂的磁盘查找会大大提高数据库查询操作的性能。
- 业务场景中判断用户是否阅读过某视频或文章。比如抖音或头条。
Demo
Go 语言中我们可以使用下面这个 package 来轻松实现一个布隆过滤器。
main.go
package main
import (
"fmt"
"github.com/bits-and-blooms/bloom"
)
func main ( ) {
m, k := bloom.EstimateParameters ( uint ( len ( md )) , 0.001 )
filter := bloom.New ( m, k )
for d := range md {
if len ( d ) == 0 {
continue
}
filter.Add ( []byte ( d ))
}
if filter.Test ( []byte ( d )) {
fmt.print ( "data already exist!" )
}
}性能比较
| 输入数据量 0.01 | Bloom 内存/ CPU 峰值 | map 内存/ CPU 峰值 | 内存节省 |
|---|---|---|---|
| 1w | 0.8MB | 1.18MB | 32.5% |
| 5w | 1.5MB | 3.3MB | 54.5% |
| 10w | 1.37MB | 3.66MB | 62% |
| 50w | 2.24MB | 23.2MB | 90% |
| 100w | 2.7MB | 46.1MB | 94% |
| 500w | 9.3MB | 191.4MB | 95% |
| 1000w | 17.6MB | 382.5MB | 95% |
| 5000w | 61.7MB | 1705.2MB | 96% |
内存占用情况:Bloom 减少 60% - 90% 的内存占用
| 输入数据量 0.01 | Bloom 查询耗时 | map 查询耗时 | 耗时增加 |
|---|---|---|---|
| 1w | 1+1=2ms | 508+508=1ms | 200% |
| 5w | 5.6+4.8=10.5ms | 3.2+3.0=6.3ms | 166% |
| 10w | 12+9.6=21.8ms | 9+6=15ms | 145% |
| 50w | 61.1+52.1=113.2ms | 51.6+47.6=99.1ms | 114% |
| 100w | 125.9+109.4=235.3ms | 136.5+121.5=258ms | 91% |
| 500w | 665.5+592=1.26s | 723.5+711.8=1.4s | 90% |
| 1000w | 1.87+1.5=3.9s | 1.48+1.4=2.9s | 134% |
| 3000w | 16.5s | 9.8s | 168% |
| 5000w | 15+13=28s | 7.6+7.6=15.2s | 184% |
全量插入 & 全量查询的耗时记录
贡献者

更新日志
2025/10/11 02:26
查看所有更新日志